
[JPA][토크ON세미나] JPA 프로그래밍 기본기 다지기 정리
[토크ON세미나] JPA 프로그래밍 기본기 다지기 - 김영한
JPA는 Java Persistence API의 약자로 자바 기반으로 개발된 응용프로그램에서 관계형 데이터베이스를 객체 지향 형태로 관리하는 자바 API를 뜻한다. 이러한 JPA 구성 요소는 아래 세 가지 영역으로 구성된다.
- javax.persistence 패키지로 정의된 API
- JPQL (Java Persistence Query Language)
- 객체/관계 메타 데이터
기초 실습
아래 내용은 김영한님의 토크ON세미나 강의를 보며 요약 정리한 것이다. 먼저 실습을 위한 준비 과정으로 간단한 maven 프로젝트를 만들고 H2 데이터베이스를 설치한다. 강의에서는 Java8을 사용하는데 기호(?)에 따라 다른 버전을 선택해도 괜찮다는 얘기가 있어 Java11로 선택했다. 실습을 진행하는 중간에 EntityManagerFactory를 생성할 때 오류가 발생하는 경우가 있는데, 아래 코드를 pom.xml 에 삽입하면 해결된다.
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.3.0</version>
</dependency>
H2 데이터베이스 설치
- http:www.h2database.com/
- 1.5MB 크기의 가벼운 최고의 실습용 DB
- 웹용 쿼리 툴 제공
- MySQL, Oracle 데이터베이스 시뮬레이션 가능
- Sequence, Auto Increment 기능 지원
객체 매핑하기
- @Entity : JPA가 관리할 객체 엔티티
- @Id : DB PK와 매핑 할 필드
persistence.xml
- JPA 설정 파일
/META-INF/persistence.xml위치java.persistence로 시작 → JPA 표준 속성hibernate로 시작 → 하이버네이트 전용 속성
Dialect (방언)
데이터베이스 방언이란 SQL 표준을 지키지 않거나 특정 데이터베이스만의 고유한 기능을 뜻한다. 실제로 각각의 데이터베이스가 제공하는 SQL 문법과 함수는 조금씩 다르다. 가변문자와 관련해 MySQL은 VARCHAR, Oracle은 VARCHAR2을 사용한다. 문자열을 자르기 위해 SQL 표준은 SUBSTRING()을 제시하나 ORACLE은 SUBSTR()을 사용한다. 끝으로 페이징을 위해서 MySQL은 LIMIT, Oracle은 ROWNUM을 사용한다.
JPA는 말 그대로 API이기 때문에 현실적으로 많이 어렵겠지만 이러한 방언에 종속적이지 않으며 개발/운영시 어느 데이터베이스를 사용하던지 손쉽게 교체, 보수 할 수 있어야 한다. 그래서 JPA는 이런 문제점을 해결하기 위해 데이터베이스 방언 클래스를 대부분의 데이터베이스별로 추상화 해놓았다. 즉, 데이터베이스가 변경되더라도 데이터베이스 방언만 교체하면 쉽게 적용할 수 있다.
Simple example code
Entity Manager Factory 설정, Entity Manager 설정, Entity Manager로부터 Transcation 생성, 비즈니스 로직(CRUD) 순서를 따르는 코드를 아래와 같이 작성한 후 실행해보자.
package hellojpa;
// javax.persistence : Java 표준 패키지
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import hellojpa.entity.Member;
public class Main {
public static void main(String[] args) {
// META-INF/persistence.xml 내부 persistence-unit 에 걸린 이름의 설정 값을 가져옴
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
// 실제 어플리케이션에서는 고객의 요청에 따라 EntityManager 만들어서 사용
EntityManager em = emf.createEntityManager();
// 트랜잭션을 얻어와 시작
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// 객체 정보 주입
Member member = new Member();
member.setId(100L);
member.setName("AmongUS");
// 객체 관리 주체에 저장 (preparedStatement 에 매핑하는 느낌)
em.persist(member);
// 트랜잭션 커밋 (반영)
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
// 객체 관리 매니저 종료
em.close();
}
System.out.println("hello");
emf.close();
}
}
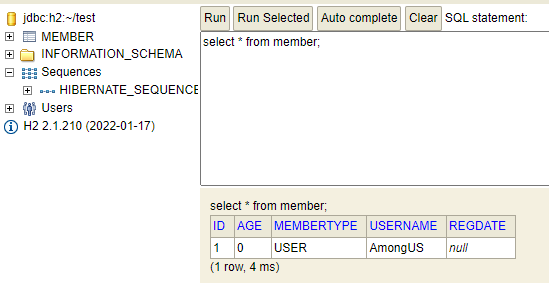
그러면 아래 그림과 같이 어떤 쿼리가 나갔는지, 데이터베이스 테이블에 값이 저장됐는지 확인 할 수 있다. 여기서 EntityManagerFactory는 하나만 생성해 애플리케이션 전체에서 공유하며, EntityManager는 쓰레드 간에 공유하지 않고 사용 후 close()를 필수적으로 수행해야 한다. 끝으로 모든 JPA의 모든 데이터 변경은 Transaction 안에서 실행된다는 것을 유념하자.
.png)
데이터베이스 스키마 자동 생성
JPA는 JPA가 직접 데이터베이스 스키마 생성이 가능하다. DDL을 어플리케이션 실행 지점에 자동 생성이 가능하는 것이다. 따라서 데이터베이스에 명세에 따른 테이블 생성을 어플리케이션 레벨에서 수행 할 수 있게 된다.
이는 테이블 중심에서 객체 중심 데이터베이스 관리가 가능함을 뜻한다. 데이터베이스 방언을 활용하면 각 데이터베이스 종류에 맞는 적절한 DDL이 자동으로 생성된다. 그러나 이러한 DDL은 개발 장비에서만 사용하는 것을 권장하고 있다. 운영서버에서는 사용하지 않거나, 적절히 다듬은 후 사용하는 것을 추천한다.
데이터베이스 스키마 생성에 사용하는 옵션으로 hibernate.hbm2ddl.auto 가 있다. 아래 persistence.xml 문서에 주석처리 된 부분이다.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- ... -->
<!-- 데이터베이스 스키마 자동 생성 -->
<!--<property name="hibernate.hbm2ddl.auto" value="create" /> -->
</properties>
</persistence-unit>
</persistence>
여기에 세부 옵션이 존재하는데, 이에 따른 동작은 아래와 같다.
- create: 기존 테이블 삭제 후 다시 생성 (DROP + CREATE)
- create-drop: create 와 같으나 종료 시점에 테이블 DROP
- update: 변경분만 반영
- validate: 엔티티와 테이블이 정상 매핑되어는지만 확인
- none: 사용하지 않음
강사님은 이렇게 데이터베이스 스키마 자동 생성 할 때 주의점으로 운영 장비에는 절대 create, create-drop, update 를 사용하지 않는다 는 원칙을 권장한다. 지금은 더욱 보수적으로 바뀌어 개발에서조차 사용하지 않는 것을 권장하며 alter 구문 역시 개발자가 직접 작성하도록 정책을 수정하고 있다고 한다.
그치만.. 로컬에서 빠르게 추가하고 싶다면 위 옵션들이 편하다고 한다. 로컬에서 혼자 개발 할 때! 그럴 때만 사용하도록 권장하고 있다. 이를 실험해보기 위해 create 옵션을 주고 컬럼을 변경 후 실행해보면 DROP 을 수행하고, 테이블을 다시 생성하는 것을 볼 수 있다. 굉장히 위험…

매핑 어노테이션
이들은 모두 테이블과 객체 변수와의 관계들을 표현한 것이다.
@Column@Temporal@Enumerated@Lob@Transient
여기서 몇 가지 팁이 있는데, @Enumerated 내부에는 EnumType.STRING 을 쓰는 것을 권장하는 것이다. EnumType.ORDINAL 은 순서 값이 입력되기 때문에 Enum 타입이 바뀌게 되면 대응 값이 모두 바뀌는 경우가 생긴다.
@Entity
@Getter
@Setter
public class Member {
@Id
private Long id;
@Column(name = "USERNAME", nullable = true)
private String name;
private int age;
@Temporal(TemporalType.TIMESTAMP)
private Date regDate;
@Enumerated(EnumType.STRING)
private MemberType memberType;
}
@Column
- 가장 많이 사용됨
- name: 필드와 매핑할 테이블 컬럼 이름
- insertable: 삽입 가능 여부 결정
- updateable : 값 업데이트 가능 여부 결정
- nullable: null 허용여부 결정, DDL 생성 시 사용
- unique: 유니크 제약 조건, DDL 생성 시 사용
- columnDefinition, length, precision, scale (DDL)
@Lob
- CLOB, BLOB 매핑
- CLOB: String, char[], java.sql.CLOB
- BLOB: byte[], java.sql.BLOB
@Lob어노테이션을 넣으면 자동으로 매핑
@Transient
- 필드는 매핑하지 않고 객체에서만 사용하는 값
식별자 매핑 방법
@Id: Primary Key 값 직접 매핑- IDENTITY: 데이터베이스에 위임
- SEQUENCE: 데이터베이스 시퀀스 오브젝트 사용
@SequenceGenerator필요
- TABLE: 키 생성용 테이블 사용, 모든 데이터베이스 종류에 적용 가능
@TableGenerator필요
- AUTO: 방언에 따라 자동 지정, 기본값
아래와 같이 @GeneratedValue(strategy = GenerationType.AUTO) 를 사용하고 실행해보면 H2 데이터베이스에서 자동으로 키 값이 생성되는 것을 확인할 수 있다. 직접 ID 값을 입력하지 않도록 sequence 가 생성된 것을 볼 수 있다.
@Entity
@Getter
@Setter
public class Member {
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
/* ... */
}
권장되는 식별자 전략
기본 키 제약 조건은 다음 세 가지를 만족해야 한다. null 이 아니며, 유일하며, 변하면 안 되는 것이다. 미래까지 해당 조건을 만족하는 자연키는 찾기 어렵다. 그렇기 때문에 대리키(대체키)를 사용하는 것을 제안하고 있다. 강의를 수행한 김영한님은 Long 타입 + 대체키 + 키 생성전략을 사용하는 것을 권장한다. 비즈니스랑 관계없는 것을 무조건 대체키로 사용하자는 것을 경험으로부터 배웠다고 한다.
연관관계 매핑
연관관계 매핑은 JPA를 사용하며 가장 많이 헷갈리는 부분이라고 한다. 나는 간단하게 현재 객체가 연관관계의 왼쪽에 위치하며 어노테이션 대상은 오른쪽으로 위치한다고 생각하고 있다. 예를 들어 아래와 같은 경우, Many는 Member, One은 Team에 대응된다. 이를 참고하고 계속해서 글을 읽어보자.
@Entity
@Getter
@Setter
public class Member {
// ...
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
아래는 테이블에 맞게 객체를 설계하는 경우이다. private Long teamId;에서 보는 것과 같이 현재 멤버가 어떤 팀에 속하는지 표시하기 위해서 객체 참조 대신에 외래키를 사용하고 있다.
@Entity
@Getter
@Setter
public class Member {
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(name = "USERNAME", nullable = true, length=20)
private String name;
private int age;
@Temporal(TemporalType.TIMESTAMP)
private Date regDate;
@Enumerated(EnumType.STRING)
private MemberType memberType;
@Column(name = "TEAM_ID")
private Long teamId;
}
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
}
위와 같이 단순 외래키 참조를 통해 연결된 두 객체를 선언한 후 아래와 같이 Main 코드를 작성하고 실행해보자. member로 선언한 객체에 팀을 추가하기 위해 member.setTeamId(team.getId());와 같이 작성된 코드를 실행한다.
public class Main {
public static void main(String[] args) {
// ...
try {
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId());
em.persist(member);
tx.commit();
}
// ...
}
}
위 코드를 수행한 결과는 아래와 같다. 데이터베이스에서는 전혀 이상이 없어 보인다. 실제로 Member 테이블과 Team 테이블은 외래키로 조인되어 서로가 서로를 참조할 수 있다. Team에서 Member를 찾을 수 있고, Member 에서 Team을 찾을 수 있다는 것이다. 그러나 객체 관계는 참조를 사용해 연관된 객체를 찾을 수 없다는 것에 주의해야 한다. 이 특징이 코드 레벨에서 verbose함을 야기시키는 원인이 된다.
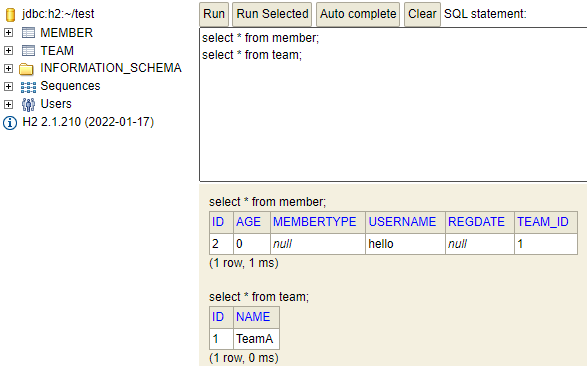
아래는 위에서 다뤘던 내용을 코드로 구현해 약간의 verbose함을 보여주는 예시다. 특정 Member와 연결된 Team 객체를 찾으려면 Member의 Team ID를 가져와서 em.find(Team.class, teamId);를 통해 해당 정보를 찾아야 한다. 동작은 하지만 코드 상에서 불필요한 동작을 여러 번 수행하고 있다.
public class Main {
public static void main(String[] args) {
/* ... */
try {
// Team 조회
Member findMember = em.find(Member.class, member.getId());
Long teamId = findMember.getTeamId();
Team findTeam = em.find(Team.class, teamId);
tx.commit();
}
/* ... */
}
}
단방향 매핑
객체의 참조와 테이블의 외래키를 매핑한다. 즉, 객체 다이어그램에서 직접적으로 참조가 가능하도록 만드는 것이다. 물론 단방향이기 때문에 한 쪽에서만 참조가 가능하다.
@Entity
@Getter
@Setter
public class Member {
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(name = "USERNAME", nullable = true, length=20)
private String name;
private int age;
@Temporal(TemporalType.TIMESTAMP)
private Date regDate;
@Enumerated(EnumType.STRING)
private MemberType memberType;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
앞서 설명했던 것처럼 관계를 설정하는 네이밍 규칙은 (현재 객체) To (타겟 객체) 를 따른다. 그렇기 때문에 관계가 설정되는 Member 는 현재 객체가 되고, 이와 관계를 가지는 타겟 객체는 Team 이 된다. 위 설명을 이해했다면 먼저 @ManyToOne 을 이용해 다대일 관계를 설정한다. Team 객체는 여러 개의 Member를 가질 수 있다는 뜻이다. 이렇게 설정만 수행하면 아래와 같이 코드가 간단해진다.
public class Main {
public static void main(String[] args) {
// ...
try {
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team); // not ID, just Team object
em.persist(member);
// 객체 참조를 통한 Team 조회
Member findMember = em.find(Member.class, member.getId());
Team findTeam = findMember.getTeam();
tx.commit();
}
}
}
FetchType.LAZY & FetchType.EAGER
em.flush(); em.clear(); 로 DB에 쿼리를 전부 보내도록 설정하면 @ManyToOne(fetch = FetchType.LAZY) 를 지정했을 때, 어떤 쿼리가 수행되는지 확인 할 수 있다. 여기서 LAZY 한 패치는 불러온 객체를 실제 사용할 때, 쿼리를 수행하도록 명령하는 것이다. 보통 모든 코드에 LAZY 를 발라놓고, 꼭 필요한 곳에서만 한 번에 가져와 성능을 확인해보며 최적화 하는 방법을 추천한다고 한다.
양방향 매핑
다시 Team과 Member와의 관계를 살펴보자. 단방향 코드에서는 Member가 어떤 팀에 속해있는지는 알 수 있으나 Team에 어떤 Member들이 속해있는지는 확인 할 수 없었다. 이제 Team 에서 Member 객체들을 참조하기 위해 Team 객체에 @OneToMany 를 추가한다.
@Entity
@Getter
@Setter
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<Member>();
}
여기서 Main.java 코드를 다음과 같이 작성해보자. 이 때, em.flush(); em.clear(); 를 지우고 한 번 실행해보자. 반영이 안 된다.
왜냐하면 em.flush() 는 반영하는 동작을 수행하고, em.clear() 는 현재 persistence context 에 있는 Member 정보와 Team 정보를 지우기 때문이다.
Persistence context 에 어떤 동작을 수행해야 하는지가 남아있는 상태에서 em.flush() 명령으로 실제 데이터베이스로 명령을 수행한다. 그러나 em.flush() 만 수행한 상태로 조회를 해보면 역시 Team에는 어떠한 Member 정보도 있지 않다. 데이터베이스에는 적용되었으나 다시 한 번 꺼내오는 작업이 수행되지 않은 것이다. em.clear()를 통해 Member 정보와 Team 정보를 지우고 다시 한 번 업데이트를 해주는 작업을 해야 비로소 우리가 원하는 정보를 확인할 수 있다.
public class Main {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setName("member1");
member.setTeam(team);
em.persist(member);
/* *************** */
em.flush();
em.clear();
/* *************** */
// Team 조회
Member findMember = em.find(Member.class, member.getId());
Team findTeam = findMember.getTeam();
for (Member memberCls : findTeam.getMembers() ) {
System.out.println(memberCls.getName());
}
tx.commit();
}
/* ... */
emf.close();
}
}
연관관계의 주인과 mappedBy
객체와 테이블이 연관관계를 가지는 방법 차이를 이해하면 mappedBy를 이해 할 수 있다. 객체 연관관계에는 멤버에서 팀으로, 팀에서 멤버로 두 가지 단방향 관계가 필요하다. 즉, 객체의 양방향 관계는 사실 양방향 관계가 아니라 서로 다른 단방향 관계 2개라는 뜻이다. 반면 테이블은 FK(외래키) 하나로 두 테이블 멤버와 팀 모두의 연관관계를 관리 할 수 있다. 그러나 객체 관계에서는 문제가 생긴다. Member를 바꾸면 MEMBER 테이블의 값이 바뀌는 것은 당연하다. 그런데 Team 객체 내부의 member를 바꾸어도 이에 해당하는 MEMBER 테이블이 바뀌어야 할까? 에 대한 의문이 생긴다.
이 의문을 해결하기 위해 연관관계의 주인(Owner)를 가지도록 하는 굉장히, 아주 굉장히 중요한 개념을 도입한다. 양방향 매핑 규칙에서 객체의 두 관계 중 하나를 연관관계의 주인으로 설정하고 다른 하나는 조회만 가능하도록 만드는 것이다. 연관관계의 주인만이 외래키를 관리하며 등록, 수정 동작을 수행 할 수 있다. 반면 주인이 아닌 쪽은 읽기만 가능하다.
앞에서 어노테이션을 읽는 법을 배웠다. 그렇기 때문에 mappedBy 역시 (현재 객체) mappedBy (대상 객체)로 해석할 수 있다. 따라서 주인은 mappedBy 속성을 사용하지 않고, 주인이 아닌 경우만 mappedBy 속성으로 주인을 지정해준다. 즉, mappedBy가 적히지 않은 Member 객체가 Ownership을 가진다.
실제로 현업에서 업데이트 넣었는데 안 되는 이유 대부분이 여기서 발생하기 때문에 중요하게 생각해야 하는 개념이라고 한다. Mendix 에서도 Entity 간 Ownership 을 지정 할 수 있는데, 아마 그 개념이 이 개념인 것 같다. JPA 를 배우면서 특히 Mendix 를 다시 이해하는 계기가 되는 중.
그럼 누구를 주인으로 해야 하는가? 강의에서는 외래키가 있는 곳을 주인으로 정하는 것을 권장한다. 즉, Member.team을 연관관계의 주인으로 하는 것이다. 반대로 Team.members는 가짜 매핑으로 조회만 가능하도록 만드는 것이다. 만약 위처럼 Member.team을 연관관계 주인으로 설정하고 Team.members에만 add 를 해주게 되면 데이터베이스 상에서 TEAM_ID 값은 NULL이 나타난다. 반대로 Member.team 에 Team 을 세팅만 해주면 Team.members에 자동으로 추가가 된다.
그러나 현업에서는? 무조건 두 군데에 집어 넣는다. 객체 지향적으로 따져보면 모두 수행하는 것이 맞다. 그리고 나중에 꼭 영속 상태를 고려하면서 코드를 짜는 것이 좋다. 객체 재활용이 습관이 된 사람들은 매우.
연관관계 매핑 어노테이션
@ManyToOne@OneToMany@OneToOne@ManyToMany: 제약 조건이 많아@ManyToOne과@OneToMany로 풀어서 사용하는게 일반적이다.@JoinColumn,@JoinTable
또한 상속 관계 매핑 어노테이션이 존재한다. 아래 어노테이션을 사용하면 데이터 상속 관계도 표현 할 수 있으며, 데이터베이스의 슈퍼 타입, 서브 타입까지 표현 할 수 있다.
@Inheritance@DiscriminatorColumn@DiscriminatorValue@MappedSuperclass
복합키 어노테이션은 아래와 같다. 키를 2개 이상 잡아서 복합키로 만드는 방법이다.
@IdClass@EmbeddedId@Embeddable@MapsId
JPA 내부 구조
작성 중…
JPA 객체 지향 쿼리
작성 중…
Spring Data JPA와 QueryDSL의 이해
작성 중…

Leave a comment